関連する I/O ポートと使い方について挙げておきます。
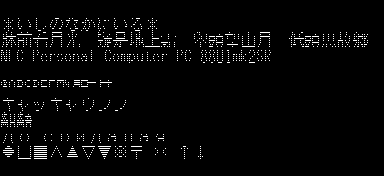
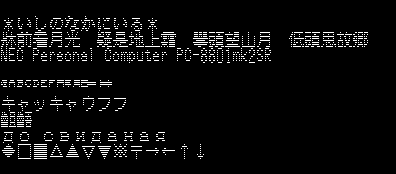
「漢字 ROM がマシンに装備されているか」を調べる際にも、とりあえず読み出してドットパターンが正常かどうか調べるのが手っ取り早いです。
| I/O ポート $E9 【入力】 |
|---|
| bit | 7-0 | 第一水準漢字フォントデータ読み出し 左半分 |
| I/O ポート $E8 【入力】 |
|---|
| bit | 7-0 | 第一水準漢字フォントデータ読み出し 右半分 |
|
| I/O ポート $E9 【出力】 |
|---|
| bit | 7-0 | 第一水準漢字フォントアドレス指定 H |
| I/O ポート $E8 【出力】 |
|---|
| bit | 7-0 | 第一水準漢字フォントアドレス指定 L |
|
漢字のドットパターンデータを読み出すためには、まずフォントデータが格納されているアドレスを
指定しなければなりません。それが I/O ポート $E8 と $E9です。
このアドレスは漢字 JIS コードを元に算出しますが、コレが非常〜に面倒くさいです。
サンプルプログラムの中にシフトJIS -> JIS -> アドレスへの変換ソースが含まれているので参考にしてください。
http://www.maroon.dti.ne.jp/youkan/pc88/index.html
参考になる。変換の仕組みが図解されています。
| I/O ポート $EA 【出力】 |
|---|
| bit | 7-0 | 漢字ROM読み出し開始サイン |
| I/O ポート $EB 【出力】 |
|---|
| bit | 7-0 | 漢字ROM読み出し終了サイン |
$EA,$EB いずれも書き込む値は何でもいいです。
FR 以降の機種では不要にになったそうです。
読み出しは書き込んだ後に 8 ステートのウェイトをとります。8MHz 機種でも 2 倍せずこのままで大丈夫そうです。
| I/O ポート $ED 【入力】 |
|---|
| bit | 7-0 | 第二水準漢字フォントデータ読み出し 左半分 |
| I/O ポート $EC 【入力】 |
|---|
| bit | 7-0 | 第二水準漢字フォントデータ読み出し 右半分 |
|
| I/O ポート $ED 【出力】 |
|---|
| bit | 7-0 | 第二水準漢字フォントアドレス指定 H |
| I/O ポート $EC 【出力】 |
|---|
| bit | 7-0 | 第二水準漢字フォントアドレス指定 L |
|
第二水準なことを除けば、$E8,$E9 と同じです。
第二水準漢字ROM は MR,FH,MH 以降のシリーズに標準搭載されているほか、マルチボードA(PC-8801-20)で拡張できます。
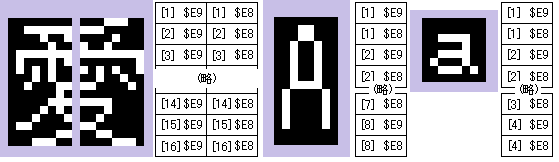
読み出しは、以下の手順を縦ドット数分繰り返します。
念のために漢字処理を行う前の初期化時にでも「読み出し終了サイン」を出力して、以下の手順が確実に実行できるようにした方が良さそうです。
- アドレス H を $E9 に書き込み
- アドレス L を $E8 に書き込み
- $EA に読み出し開始サインを書き込み。値は何でも良い。(FR 以降の機種は不要)
- CPU 8 ステート分ダミー命令で待つ
- $E9 から 1byte = 8 ドット分のデータ(左半分)を読み出し
- $E8 から 1byte = 8 ドット分のデータ(右半分)を読み出し
- $EB に読み出し終了サインを書き込み。値は何でも良い。(FR 以降の機種は不要)
以上が 1 セット分のデータ読み出しです。全角フォントはこれを 16 回、半角フォントは 1 セットで縦 2 行分読み出せるので 8 回、
1/4 角フォントも縦 2 行分読み出しなので 4 回繰り返します。
図の [ ] 内の数字がセット。必ず $E9,$E8 の両方を読みます。
手順 1. のアドレス H は、一番最初に一回書き込むだけでも大丈夫です。繰り上がりはしないので、下位アドレスだけの書き込みでも可。
サンプルプログラムに読み出しと描画のソースが含まれているので参考にしてください。
半角と 1/4 角文字は第一水準 ROM に格納されています。第二水準 ROM は漢字のみです。
200 ラインモードだと縦長になりますが、400 ラインモードにすると大変見栄えがよくなります。
PC88 でもワープロが結構実用的に動いていたので、ユーザーによっては最も活用された機能の一つではないでしょうか。