ゲームの高速化にはコードをカリカリ弄るよりも、ゲームのロジックやアルゴリズムを改良した方が手っ取り早く、
効果も高い事が多いですが、P6 レベルのマシンパワーでは、実行頻度の多いループの最深部の高速化も避けては通れません。
今回はキャラクターの描画に注目してみます。
40 以上のキャラクターがそれぞれ画像データ数十バイトを VRAM に毎フレーム転送するので全体ではかなりの負荷になりますが
ここが高速化できれば全体の速度がぐっと上がります。
P6 にはスプライトなどという高級なものはありませんので、描画と同じように消去も自前で行わなければなりません。
画面外にはみ出したらメモリの VRAM 範囲外にそのまま誤爆してしまいますし、キャラ同士が重なってもベタで上書きされます。
しかし今回は仕様としてキャラクタは常に動き回っており静止しているものはありません。動き回っているということは
キャラクタが重なっても常に更新され続けているので欠けて見えるのも一瞬のことで大して気にはなりません。
こうした仕様も味方にして高速化できるところを考えていきます。
まず、キャラクターの仕様から。
「キャラクターを高速に描画する」の前に「高速に描画できるキャラクターを考える」ことが肝心です。
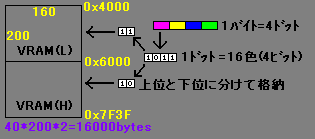
P6 の Screen Mode 3 は 160x200ドット 16色です。
図のような 1 バイトにつき 4 ドットの横長ドットで、160 ドットは横に 40 バイトの並びになります。
VRAM(L)には 16 色の下位のみが 40*200 バイト並び、VRAM(H)は上位のみです。
1 バイトが 4 ドットなので、横 8 ドット(2バイト) * 縦 16 ドット(16バイト)あたりがキャラクタとして適当なサイズです。
しかし、横 8 ドットキャラを左右に動かすと、3 バイト書き込みになる場合があり描画処理が複雑になります。
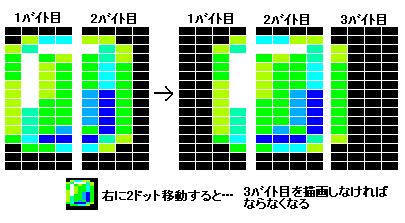
そこで 8*16 キャラはあっさり諦めます。代わりに 6*12 キャラで考えてみます。
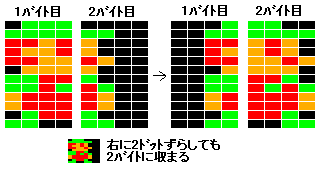
これならはみ出さずに済みます。上の状態からさらに右に 2 ドット動かしたとしても左側の状態に戻るのが分かると思います。
ただし、横 6 ドットでキャラクタを表現する難易度はかなり高いです。
先ほどから「右に 2ドット動かす」と書いていますが、なぜ 1 ドット単位ではないのか。
答えは「遅いから」です。かと言って、4 ドット(半キャラ)単位で動かすとカクカクしすぎてアクションゲームとしては致命的です。
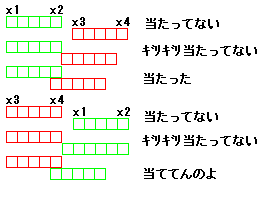
6*12でも 1 ドットずつ動かすと 3 ドット動かした際にはみだす部分が出来る点もデメリットです。

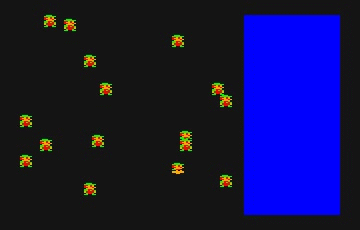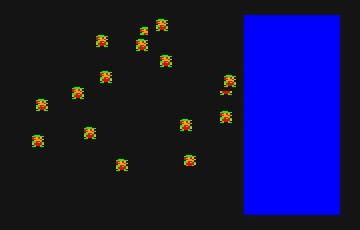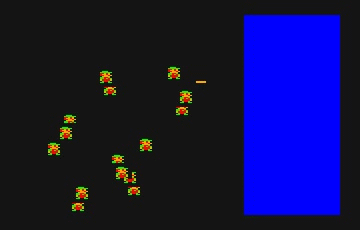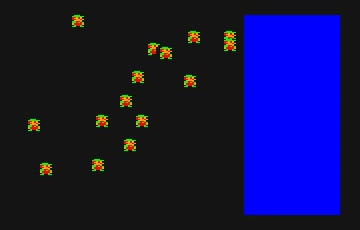
ちなみにこちらが 1 ドットずつ動かした例。ヒゲは 8 体です。変換後の GIF が 10 fps なので全然なめらかではないですが。
案外実用的?と思われるかもしれませんが、全力でやってこの速度です。ただし描画最適化なし。
それから、当然ながらキャラクタは右にシフトした状態としていない状態の 2 種類作ってメモリに配置しておきます。
描画する直前になってシフトしていたら高速化の努力が台無しなので。描画するときに x 座標の偶数奇数で描き分けます。
さて、キャラクタのサイズも決まったところで VRAM に転送するわけですが、転送先の VRAM アドレスはどうやってきまるかというと
|
VRAM = 0x4000 + (y * 40) + (x / 4) |
が VRAM(L) で、VRAM(H) は 0x4000 が 0x6000 になります。(x=0〜159 y=0〜199 の場合)
しかし、先ほど横に 2 ドットずつ動かす(=ドット縦横比から縦には 4 ドット)と決めたので、x と y の範囲は(x=0-79 y=0-49) となります。
実画面解像度(160*200)とゲーム画面解像度(80*50)の違いですね。これを適用すると VRAM アドレスは
| VRAM = 0x4000 + (y * 40 * 4) + (x / 2) |
となります。80*40 だとアイコンを縦横 2 つ並べたら隠れてしまう程度の解像度ですが、それでも半キャラずつ動かすよりはマシなのです。
x の方は 2 で割る部分は右シフト 1 回で代用できます。
これに対して面倒なのは y*40*4 の部分で、Z80 には掛け算はありませんので、シフトと足し算を組み合わせて 160 倍することになります。
どうせ y の範囲は 0〜49 しかないので、ここはテーブル化して y*40*4 の結果をあらかじめ持っておくことにします。
テーブルは全部で 2*50=100 バイト。アドレスを求める部分も出来るだけ速い方が良いでしょう。
GETADR:
LD L,E ;E=Y(0-49) D=X(0-55) とする
SLA L ;2倍
LD H,XYTABLE >> 8
LD A,D
RRA ;x>>1
ADD A,(HL) ;桁上がり無し保障
INC L
LD H,(HL)
LD L,A
RET
XYTABLE:
DW 0*40*4, 1*40*4, 2*40*4, (略)
|
テーブルはアドレス xx00 から始まる位置に配置してテーブル参照にかかるコストを最小化します。
このルーチン自体も RST 命令で呼び出せる配置にするのも手ですが、短いので描画ルーチンに組み込んでしまう方がいいかもしれません。
今回はフィールドの幅を 0〜55 に制限します。この範囲でなら同じ y 座標の中でなら桁上がりが起きないので
(x>>1) を足す部分を 16bit 加算でなく 8bit 加算に出来ます。以下、ゲームフィールド外は青い部分で示します。
さて、アドレスも求まったことですし実際に描画してみます。
ここでちょっと話を端折って、いきなり pop-ld 転送でいきます。ldi など 1 バイトずつ転送する方法は速度面で不利なので。
DRAW: ;HL=キャラデータ DE=VRAMアドレス
LD BC,39
DI
LD (.STACK+1),SP
LD SP,HL
EX DE,HL ;SP=CHR HL=VRAM
REPT 12
POP DE
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
ENDM
LD DE,0x2000-40*12
ADD HL,DE
REPT 12
POP DE
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
ENDM
.STACK:
LD SP,0000 ;ここに直接書き込み
EI
RET
| 
|
pop-ld 転送というのは、pop 命令が 1 命令で 2 バイトずつメモリから値を読み出せる(しかも読み出し位置は自動更新)ことを利用して
高速に転送を行う処理です。ldi 命令のように hl,de,bc をフルに使ったりしないのでレジスタにも余裕ができます。
反面、スタックポインタを使う関係上、その処理中には call 命令等は禁止、割り込みも入らないようにしなければなりません。
上の例では長くなるのでまとめてしまっていますが、ループ回数は 12 でなく 11 にして 1 回分を外に追い出し add hl,bc を省きます。
さて、ここまでは基本。ここから削れるかどうかがこの章の主旨です。
VRAM(L) から VRAM(H) へ書き込み先を変更する処理は ld de,0x2000-40*12 と add hl,de で 2 命令 10+11=21 ステートですが、
よく考えると VRAM(L) を左上から右下へ向かって書いたのであれば、そのアドレスから VRAM(H) は右下から左上に戻ればいいですよね。
というわけで set 5,h と ld bc,-39 に書き換えて 8+10=18 ステートに縮まりました。わずか 3 ステートでもやらないよりマシ。
ただし、VRAM(H) に書き込むデータは下から上になるようにフォーマットを変更しなければなりません。
ここで bc は 39 のままで sbc hl,bc にすれば…と思うかもしれませんが、add が 11 ステートなのに対し sbc は 15 なので相当遅くなるのです。
まだ縮まるところは無いでしょうか。
キャラクタは横に 2 バイトを縦に 12 回書き込むのですが、縦 12 回の中で横 2 バイトの inc hl が繰り上がらない回が無いか
全座標(0〜55,0〜49)について調査してみます。すると、キャラクタの line=0,4,8 の描画時は繰り上がりが絶対に発生しないことが分かりました。
つまり 24 回(12回*L/Hの2回)ある inc hl の中の 6 回は inc hl を inc l に変更できるということです。
これで 6 ステート * 6 を 4 ステート * 6 に減らせます。合計で 12 ステートの高速化。
さきほどのと合わせて 1 キャラにつき 15 ステートですが、40 キャラ描画すると 600 ステート分浮きます。結構デカい。
これで満足…していると音楽や演出を付け足していったときに残念なことになります。
キャラクタが少なければ大丈夫なのですが、どうしても速度が足りない場合はキャラクタの仕様の方を変えてしまう方法もアリです。
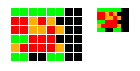
キャラクタ仕様を 6*6 ドットに変更します。
6*6 ドットといっても、横長ドットを 2 ライン続けて同じものを描くという意味なので、見かけ上のドット比は 1:1 になります。
ドット打ちがさらに職人芸を要求するようになります。文字ですら 8x8 ドットとかなのに…。
DRAW:
LD BC,39
DI
LD (.STACK+1),SP
LD SP,HL
EX DE,HL
REPT 3
POP DE
LD (HL),E
INC L
LD (HL),D
ADD HL,BC
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
POP DE
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
ENDM
SET 5,H
LD BC,-39
VRAM(H) は(略)
.STACK:
LD SP,0000
EI
RET
|
6*6 キャラとこれまでの改良点を盛り込みました。ループ回数は 3 回ではなく(同上・以下略)
pop 1 回で実質 4 バイト分読み込んでいるようなものです。VRAM(H) は省略していますが、書き込む順序は d->e かつ dec hl になります。
何?まだ遅い? うーむ仕方ない。。。
縦 2 ラインに同じものを描くのであれば、どちらか欠けていてもちょっと暗くなる程度だよね?横長ドットに戻るだけだよね?と自分を納得させつつ
スキャンライン描画方式を導入してみます。描画処理 12 ラインのところを 1 ライン飛ばしで 6 ラインにしてしまいます。
DRAW:
LD BC,40+39
DI
LD (.STACK+1),SP
LD SP,HL
EX DE,HL
.PATCH:
REPT 3
POP DE
LD (HL),E
INC L
LD (HL),D
ADD HL,BC
POP DE
LD (HL),E
INC HL
LD (HL),D
ADD HL,BC
ENDM
SET 5,H
LD BC,-40-39
VRAM(H) は(略)
.STACK:
LD SP,0000
EI
RET
| 
|
残骸がチラついているのは GIF 化が原因。
描画と同じくらい大事なのが消去です。描画と同じ回数だけ発生しますので、こちらも手を入れれば入れた分だけ速くなります。
こちらも、繰り上がりの無い VRAM アドレスは 8bit インクリメントに変えて高速化します。
CLEAR:
XOR A
LD DE,-0x2000+40*2
REPT 3
LD (HL),A
INC L
LD (HL),A
SET 5,H
LD (HL),A
DEC L
LD (HL),A
ADD HL,DE
LD (HL),A
INC HL
LD (HL),A
SET 5,H
LD (HL),A
DEC HL
LD (HL),A
ADD HL,DE
ENDM
RET
ENDIF
|
以上、スキャンライン版。
消し方は描画の時と違い、VRAM(L) と (H) を交互に消していった方が速くなります。
pop-ld と同様に push を使って消す方法もあるのですが、2 バイト程度ではこちらのほうが速いようです。
その他、重要度の低いエフェクトなどのキャラクタは 16 色使って描かなくても良いものがあります。
そういったキャラクタは VRAM の (L) か (H)、どちらか片方のみを使用し、描画回数を半分に削減します。
色数が 16 色から 4 色に制限されますので、ここもドット打ち技術の見せ所(という名のしわ寄せ)。
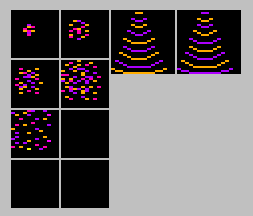
他にもフォント専用の描画処理など、まだまだいろいろあります。
上のエフェクトにしても専用の描画処理を組むので、最終的に消したり描いたりする処理が沢山できあがります。
その中で、速くなくて良いものやサイズを気にしなければならないものなど、用途に合わせた作りにしないと
P6mk2 というマシンで満足に動かすのはなかなか難しいのです。
「ガントレット」が出来るほど大量に動かせるといいんですけどねぇ。