.NET Framework 4.8 以上が必要です。Windows Update で入手できます。
Gameboy Color 専用(モノクロ GB は不可)です。GDMA 等の拡張機能を使用するためです。
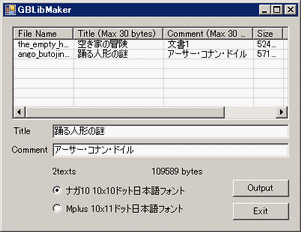
GBLibMaker はテキスト文書を GBテキストリーダーに組み込んで ROM 形式で出力します。
GBLibMaker.exe と gblib_mplus.bin, gblib_naga10.bin は同じ場所に置いてください。
使い方は以下の通り。
テキストファイル(複数可)をドラッグ&ドロップで放り込むと、リストに登録されます。
登録したテキストを選択して、タイトルとコメント(半角 30 文字、全角は 15 文字まで)を編集します。
何も書かないとそれぞれ『Title + 番号』、『Comment + 番号』となります。
登録を取り消したい場合は Delete キーを押してください。
テキストの順番はカーソルキーの上下で入れ替わります。
GB で表示する際の「ナガ10」「Mplus」の 2 種類のフォントを選ぶことができます。
設定が終わったら Output ボタンを押すと GBLIB.GBC という ROM ファイルが出力されます。
ROM の最大サイズは 2MB なので、あまり多くのテキストは入れられません。

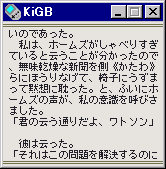
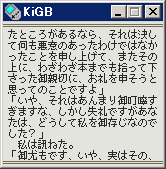
スクリーンショットのテキストは青空文庫を利用させて頂いたものです。
文字フォントとして永尾制一氏作のナガ 10 を使用させていただいています。
knj10-1.1 より 5x10rk と knj10 を GB 用に加工・収録しました。
→ナガ10 (https://github.com/chocolatemelt/naga10) 元々のサイトが消失したようなのでミラーのリンクを貼っておきます。
別の文字フォントとして M+ FONTS PROJECT による M+ BITMAP FONTS を使用させていただいています。
mplus_bitmap_fonts-2.2.4 より mplus_j10r と mplus_j10b-jisx0201 を元に GB 用に加工・収録しました。
→ M+ BITMAP FONTS (https://ftp.kaist.ac.kr/macports/distfiles/mplus-fonts/) こちらも消失したようなのでミラーリンク。
一番左端はタイトル画面で、下二行にテキストのタイトルとコメントが表示されます。
パッドの上下でテキストの選択、START でテキストリーダー画面に切り替わります。
START のみの押下で前回読んだページから、SELECT+START で強制的に最初のページから開始します。
パッドの左右または A/B ボタンでページの送り/戻しが出来ます。
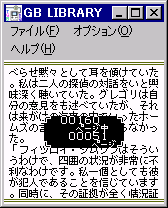
SELECT ボタンを押している間はページメニューが開きます。
その状態で上下左右キーでページ数を増減するとページジャンプができます。
START ボタンを押すことで、タイトルに戻るとともにセーブします。
次回同じテキストを開いたときに、そこから再開できます。